OpenAI 的 o3 AI 模型在基准测试中的表现低于宣传描述
 站长云网
站长云网OpenAI 的 o3 AI 模型的第一方和第三方基准测试结果之间的差异引发了人们对该公司透明度和模型测试实践的质疑。OpenAI于 12 月发布 o3时,声称该模型能够解答 FrontierMath(一组颇具挑战性的数学问题)中略高于四分之一的题目。这一成绩远远超出了竞争对手——排名第二的模型也只能正确解答 FrontierMath 题目的 2% 左右。
OpenAI 首席研究官 Mark Chen在直播中表示:“目前,所有产品在 FrontierMath 上的得分都不到 2%。我们内部看到,在激进的测试时间计算设置下,o3 的得分能够超过 25%。”
事实证明,这个数字很可能是一个上限,由 o3 的一个版本实现,其背后的计算能力比 OpenAI 上周公开发布的模型更强。
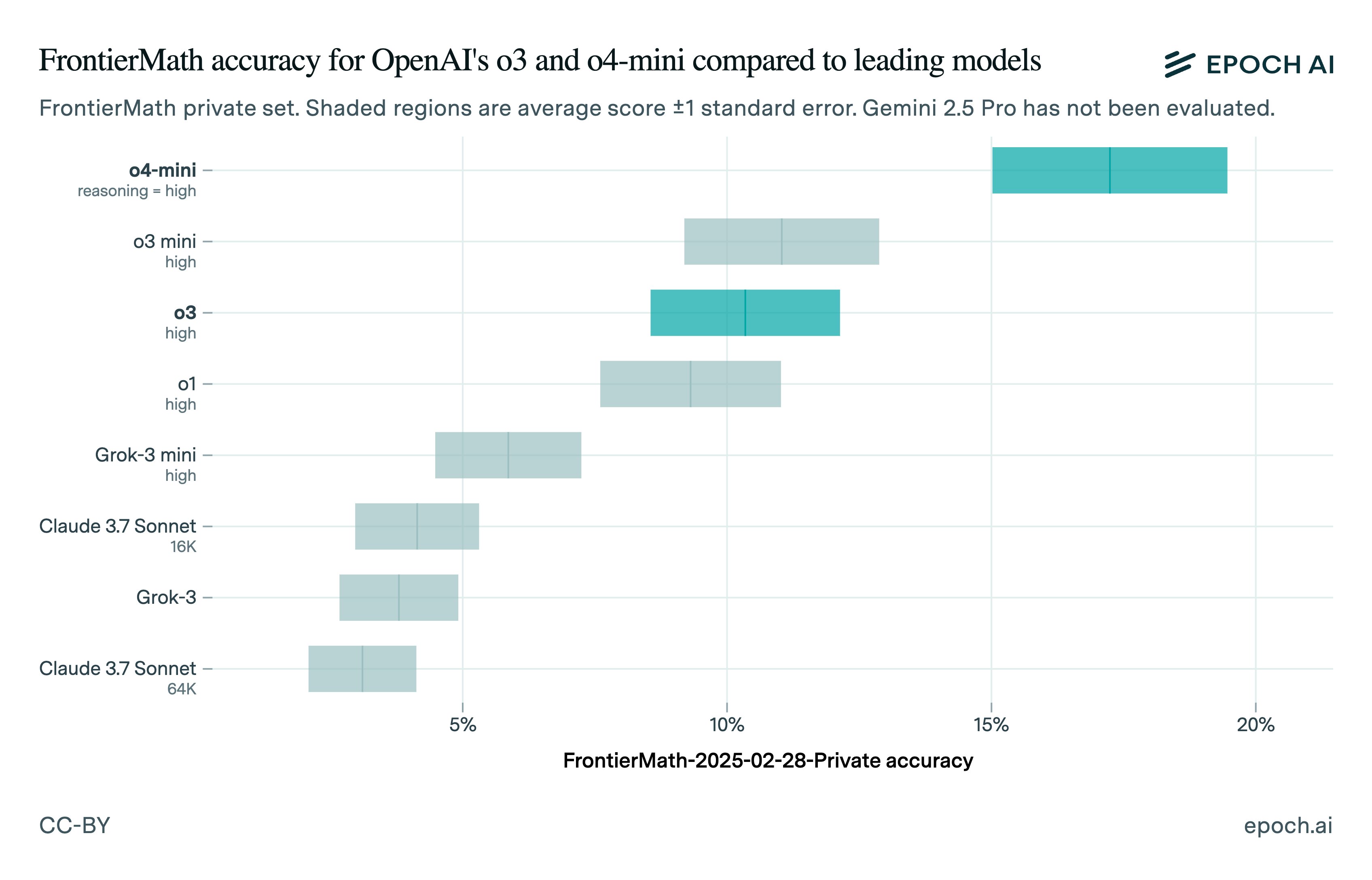
FrontierMath 背后的研究机构 Epoch AI 周五公布了其对 o3 的独立基准测试结果。Epoch 发现 o3 的得分约为 10%,远低于 OpenAI 宣称的最高得分。
这并不意味着 OpenAI 本身撒了谎。该公司 12 月发布的基准测试结果显示,其得分下限与 Epoch 观察到的得分一致。Epoch 还指出,其测试设置可能与 OpenAI 不同,并且其评估使用的是 FrontierMath 的更新版本。
Epoch 写道:“我们的结果与 OpenAI 的结果之间的差异可能是由于 OpenAI 使用更强大的内部支架进行评估,使用了更多的测试时间[计算],或者因为这些结果是在 FrontierMath 的不同子集上运行的(frontiermath-2024-11-26 中的 180 个问题与 frontiermath-2025-02-28-private 中的 290 个问题), ”
根据ARC 奖基金会(一个测试过 o3 预发布版本的组织)在 X 上的一篇文章,公共 o3 模型“是一个针对聊天/产品使用进行调整的不同模型”,证实了 Epoch 的报道。
ARC Prize 写道:“所有已发布的 o3 计算层都比我们[基准测试]的版本要小。” 一般来说,更大的计算层有望获得更好的基准测试分数。
OpenAI 的技术人员周文达 (Wenda Zhou)在上周的直播中表示,与 12 月演示的 o3 版本相比,生产版 o3“针对实际用例进行了更优化”,速度也更快。因此,它可能会表现出基准测试的“差异”,他补充道。
“我们已经做了一些优化,使这个模型更具成本效益,并且总体上更有用,”周说道。“我们仍然希望——我们仍然认为——这是一个更好的模型[…] 当你需要答案时不必等待太久,而这些[类型的]模型确实做到了这一点。”
诚然,o3 的公开发布未能达到 OpenAI 的测试承诺这一事实有点无意义,因为该公司的 o3-mini-high 和 o4-mini 模型在 FrontierMath 上的表现优于 o3,而且 OpenAI 计划在未来几周推出更强大的 o3 变体 o3-pro。
然而,这再次提醒我们,最好不要只看表面价值来理解人工智能基准——尤其是当其来源是一家出售服务的公司时。
随着供应商竞相利用新模型吸引眼球并抢占市场份额,基准测试“争议”正在成为人工智能行业的常见现象。今年 1 月,Epoch因迟迟未披露 OpenAI 的资助而受到批评,直到 OpenAI 宣布 o3 项目后才披露。许多为 FrontierMath 做出贡献的学者直到 OpenAI 公开宣布后才得知此事。
最近,埃隆·马斯克的 xAI 被指发布了其最新 AI 模型 Grok 3 的误导性基准图表。就在本月,Meta 承认其吹捧的模型版本基准分数与该公司向开发人员提供的版本不同。
踩一下[0]
顶一下[0]